产品简介

光直连GPU超节点系统
光子算数自主研发的人工智能硬件方案,采用先进的光电融合技术,将光互联芯片与国产GPU芯片板卡集成,实现GPU加速卡间的直接高速互联,突破传统电互联瓶颈,为大规模AI计算提供高效能支撑,奠定中国人工智能行业算力新基础。
产品优势
-

GPU光直连技术
采用线性直驱光互联技术,具备低延时、高带宽、低功耗的显著优势,实现GPU芯片直接出光,构建光直连GPU超节点,大幅度提高整机柜算力密度,实现更加高效的算力供给。 -

“硬、网、软” 协同
以 “硬、网、软协同” 的系统级创新,依托光互联和光电集成技术积累,与国产GPU芯片深度协同设计,打造光电融合的光直连GPU加速卡,实现光电协同。 -

新一代高效AI算力底座
采用标准协议,支持国内主流GPU芯片,实现GPU芯片直接驱动光信号,用于构建大规模GPU芯片间高效通信网络,在兼容性、算力、互联带宽等方面具备显著优势。
核心组件
- 光直连GPU加速卡
- GPU光直连网络架构
- 光电混合软件栈
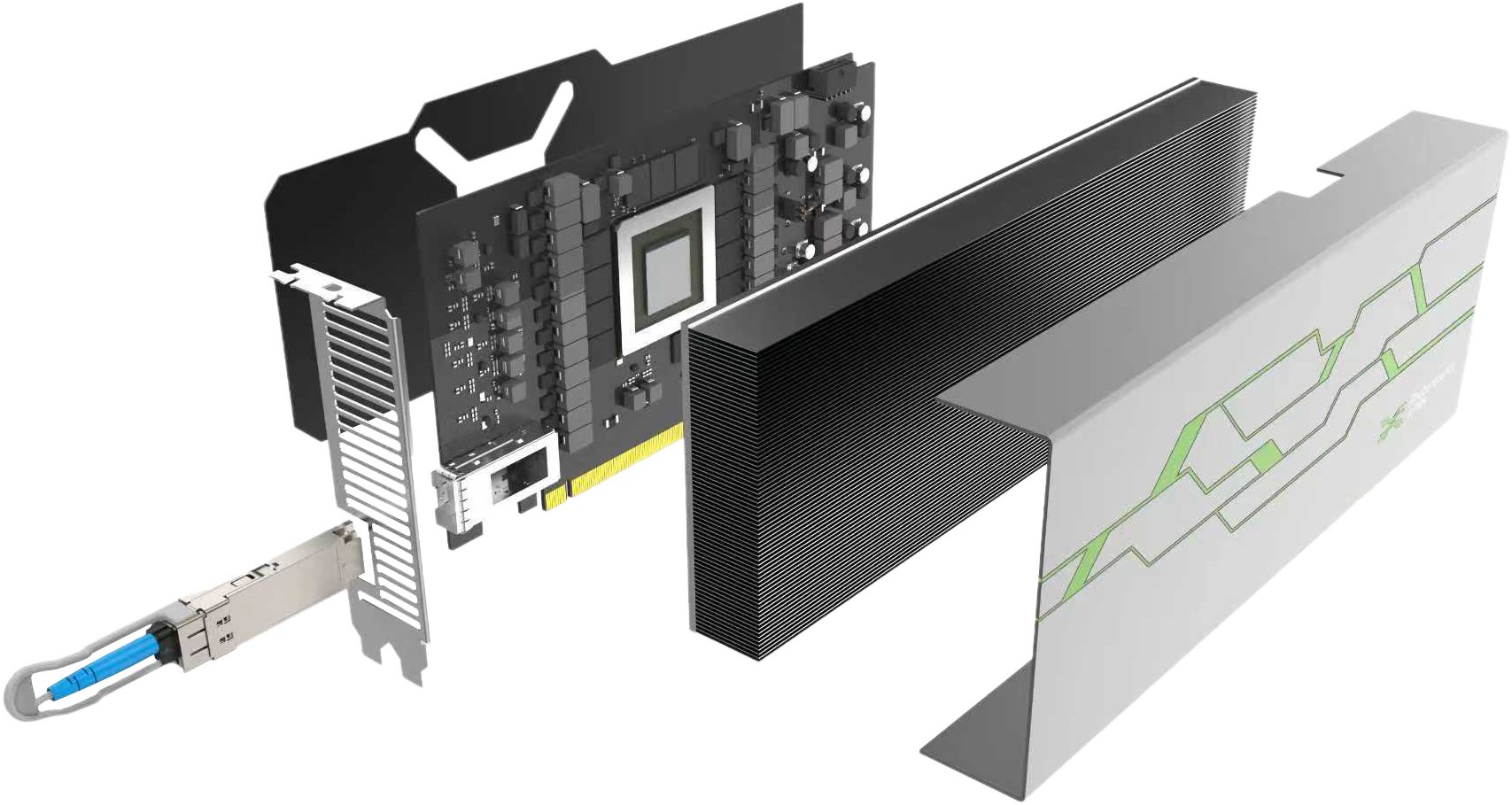
光直连GPU加速卡
采用GPU光直连技术,兼容主流国产GPU芯片,实现GPU间高速光直连,可广泛应用于大模型训练、推理场景,为各行业提供高能效比、高带宽、低延时的高性能算力支撑。
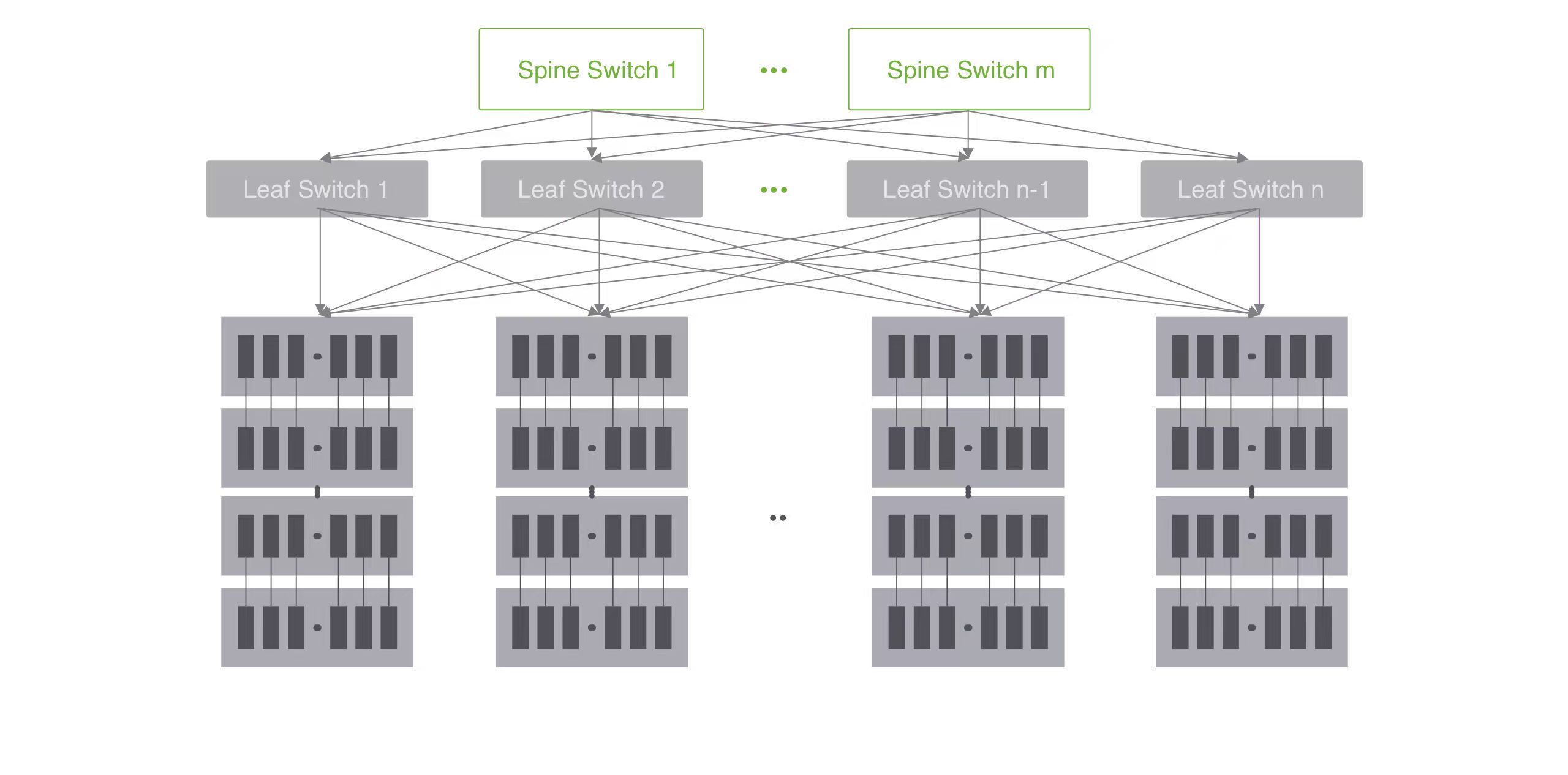
GPU光直连网络架构
GPU 光直连可有效突破跨机柜连接限制,助力实现规模更大、扩展性更强的 Scale Up 算力域,构建 320 卡光直连 GPU 超节点系统,推动高性能计算集群向全光架构演进。
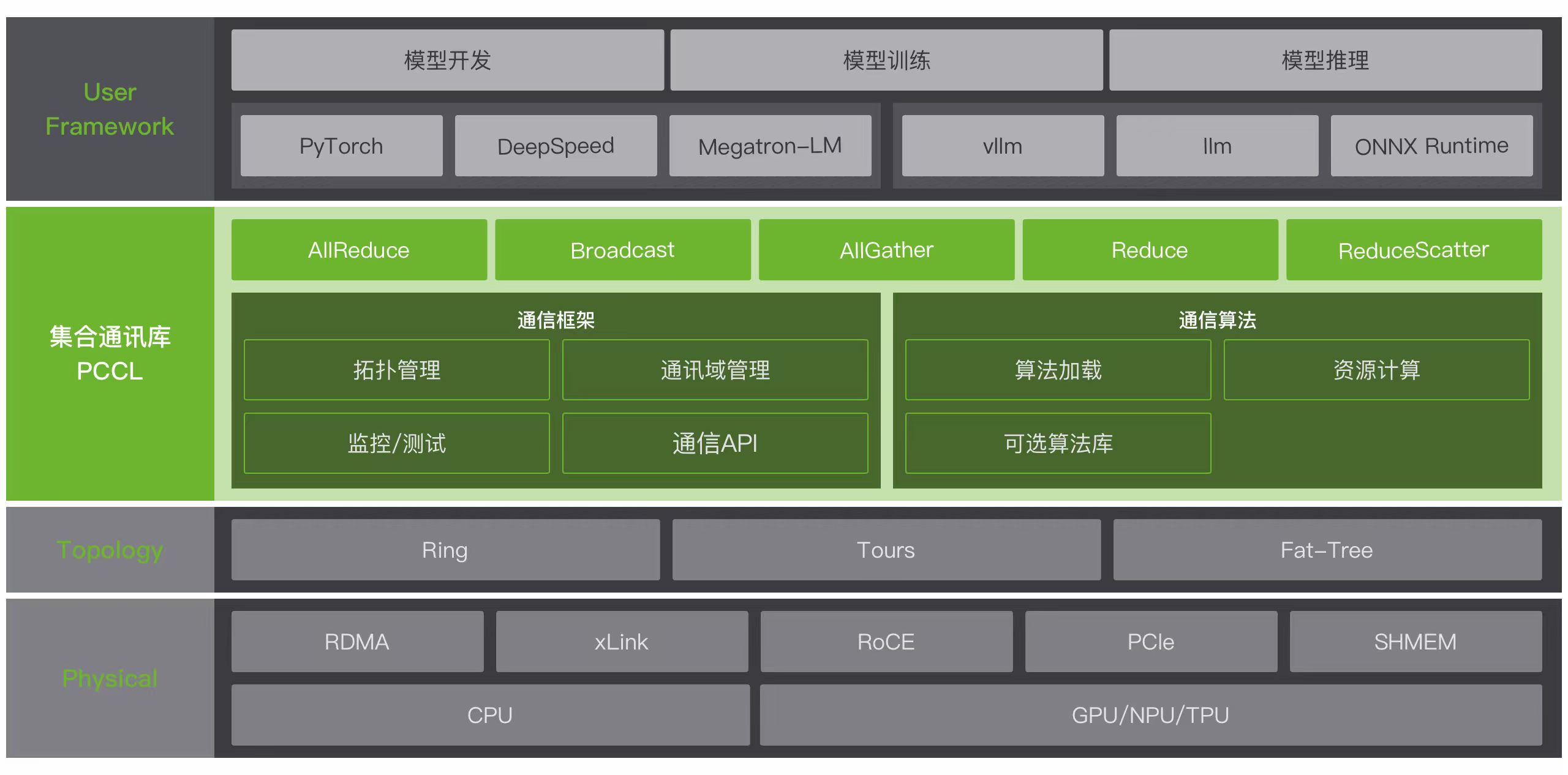
光电混合软件栈
设计光电混合软件栈,特别是集合通信库,实现通信与计算协同、软硬相适配,提升基于 Transform 架构的 AI 大模型计算效率。